Quote o' the day: Picking acronyms
Apparently, Frank McSherry’s laptop is called ‘Echidnatron’.
From COST in the land of databases, by Frank McSherry, we have…well, we have an interesting blog post. But for my purposes here, we have a quote:
Our first paper is Scalable Distributed Subgraph Enumeration or “SEED”. We will have a future post about rules for picking acronyms.
Lookin’ forward to it.
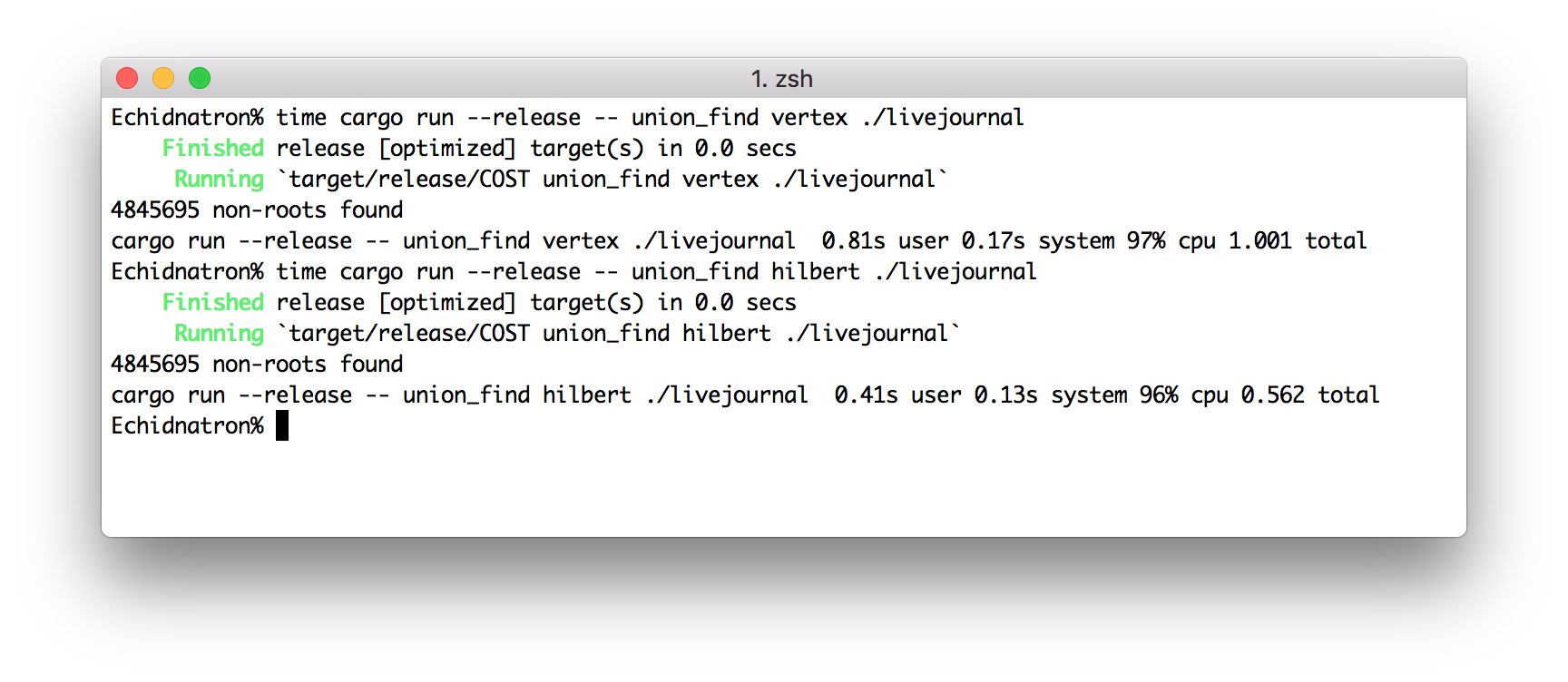
Update: Then there’s this, always something to explore in systems work:
That demonstrates non-triviality, in that their system isn’t just a laptop computing the answer and 156 cores mining bitcoin.
And later:
First, let’s check out the CIDR measurements, which include fewer of the graph processing systems (Giraph and GraphLab) because apparently they run out of memory or crash or whatever. It’s ok to make fun; they’ve all made lots of money.
Re-Update: Dangit.
I do have more questions about their paper, but they are “what does your theorem actually mean” questions rather than “what neurotoxin did you coat your submission with” questions. I think that is progress.