A deep dive into regular expression derivatives for lexical analysis
Although I (embarrassingly) never completed the project, I have written before on derivative-based parsing,1 the work of Matt Might and others. The recent appearance of On the Complexity and Performance of Parsing with Derivatives and a certain immediate interest in parsing re-awakened my curiosity about the subject. (And no, it’s not because Might’s derivative-parsing tool is called Derp (but as an added bonus, the pure recognizer version is “herp” (and the accompanying regular expression package is “rerp”)).2) In this particular post, I would like to demonstrate why I think the technique is cool, by demonstrating that derivative-based regular expressions are cool.
To that end, I’ll start with regular expression matching, then go on to the conversion to a deterministic finite automaton and finally discuss the minor extras needed to build a lexical analyzer, similar to lex or flex (but better).
Introduction
I have written about regular expressions before, too.3 They are cool, they are useful, they are fairly simple to understand and work with…what’s not to like? Even better, how about a way of working with them that does not involve a trip into non-determinism land? Hence, Regular expression derivatives reexamined, by Scott Owens, John Reppy, and Aaron Turon. Let’s take a closer look at that.
The usual preliminaries
When I was taking classes in graduate school, I noticed something peculiar: every professor, in every class, spent a couple of sessions on predicate logic, usually first-order predicate calculus. Naturally, all of the introductions were different in some aspect or another. And, I had gone into graduate school with a pretty fair understanding of predicate logic courtesy of an excellent undergraduate course on the subject. Now, I recognize that all of the incoming students from various places could not be assumed to have had a brilliant introduction to the topic, nor to have followed the same schedule as I did, and further, it is an important topic to computer science…but geeze. Couldn’t they have compared notes or something?
As a result, I spent some of the first few class sessions doing one of two things: napping or becoming confused. Neither is especially a good way to start a computer science class, although napping is probably does the lesser harm. Eventually, I got to the point where I no longer really understood predicate calculus, and to this day, I could not come up with a coherent description of it.
At the risk of causing someone else to suffer my pain, here is my brief introduction to regular expressions. Feel free to take a nap.
This section starts with a basic definition of regular expressions and the terminology around them, and then goes into the definition of the derivative of a regular expression. We will do something useful with them in the next section.
A regular expression starts with an alphabet, Σ, containing a finite number of basic symbols; think of the ASCII characters or Unicode or something. A string is a sequence of symbols from Σ, kind of like this sentence. Σ* is the Kleene-closure (more on this in a minute) of the alphabet; i.e. the set of all strings that can be constructed from the alphabet, by gluing together zero or more symbols. Note that Σ* is infinite; although every string has some finite length, Σ* includes every string. This set does include one special member, ϵ, which represents the string with zero components, the empty string.
A language is a subset of Σ*, dividing that set of strings into those strings that are in the language and those strings that are not in the language. There is one special language, ∅, consisting of the empty set; all strings, including ϵ, are on the “not in the language” side.
A regular expression is a (relatively) concise description of a (simple) language. (There are many other ways of describing languages, such as grammars (context free, context sensitive, and “I acknowledge there is a context but I don’t have the social skills to follow it”), but regular expressions, or regexs, or even regexps, are the topic here.)
Regular expressions are built from the symbols of the alphabet Σ, combined using a specific group of operations:
Concatenation. If a and b are symbols, ab is the regular expression describing the language {ab}; i.e. the language containing the string consisting of a followed by b.
Alternation. If a and b are symbols, a|b describes the language {a, b}; i.e. the language containing the two strings, a and b.
Kleene-closure. The Kleene star operator, *, is kind of special; it says, “any number, zero or more, of copies of whatever is in front of it.” If a is a symbol, the regular expression a* describes the language {ϵ, a, aa, ...}. Unlike the two examples above, this language contains an infinite number of strings. (That should explain what Σ* means; it is another use of the Kleene star.)
In the examples above, I used the simplest regular expressions, the symbols a and b. All of these operations work for “sub-expressions” similar to arithmetic operators: if r and s are regular expressions, rs is the regular expression describing the language built from the languages described by r and s, where every member of the language rs is a string consisting of a prefix from the language r followed by a suffix from the language s. The language described by r|s is the union of the languages described by r and s, and the language described by r* is the language made up of zero or more concatenated copies of the strings in r.
For our use here, this relatively normal description of regular expressions is extended with two other operations. While these operations are not normally seen in descriptions of regular expressions, they do not add anything; theoretically, they can be built from the operations above.
Conjunction. If r and s are regular expressions, r ∧ s describes the language consisting of those strings that are in both r and s.
Negation. If r is a regular expression, ¬r describes the language consisting of strings that are not in the language r.
Finally, feel free to add parentheses to resolve any ambiguity in the expression.4
So what’s the derivative of my left elbow?
Given the brief introduction above, what is the derivative of a regular expression? It certainly has nothing obvious to do with differential calculus, that’s for sure.
The derivative of a regular expression r, with respect to a symbol a, is another regular expression, call it r′. The language described by r′ consists of all of the strings from the language of r that start with a, with the a prefix stripped off. Here’s some examples:
The derivative of ab (i.e. the language {ab}) with respect to a is the set of strings from the original language that start with a (i.e. {ab}) with the initial a stripped off: {b}. This is the regular expression b.
The derivative of ab ({ab}, remember) with respect to c is the set of strings from the language described by ab that start with c, with the c removed: the empty set, ∅. (For simplicity (if not clarity), let’s say that the language ∅ is represented by the regular expression ∅.)
The derivative of a* (the set {ϵ, a, aa, ...}, remember) with respect to a is the set of strings described by a* with the initial a removed. The ϵ is removed from the set, but it is replaced by a with the a removed, which is itself replaced by aa with its initial a removed: a. So, the language of the derivative r′ is still {ϵ, a, aa, ...}. The derivative of a* with respect to a is simply a*. Neat, eh?
The language of the derivative of a|b with respect to a is the subset of {a, b} of strings starting with a, which is {a}, with the a prefix removed: {ϵ}. (For convenience, this language is described by ϵ, treated as a regular expression. Can’t make this stuff too easy, ya’ know.)
The paper, “Regular-expression derivatives reexamined”, gives the following simple, mathematical definition of the derivative of a regular expression with respect to a character, a. (The notation δ(r, a) stands for the derivative of r with respect to a (and yes, I simplified the notation used in the paper, because a subscript does not make any damn sense as an argument).)
$$
\begin{array}{rcl}
\delta(\epsilon, a) & = & \emptyset \\
\delta(a, a) & = & \epsilon \\
\delta(b, a) & = & \emptyset\ \textrm{ when $a \neq b$} \\
\delta(\emptyset, a) & = & \emptyset \\
\delta(r \cdot s, a) & = & (\delta(r,a) \cdot s) | (\nu(r) \cdot \delta(s,a))\\
\delta(r*, a) & = & \delta(r, a) \cdot r* \\
\delta(r|s, a) & = & \delta(r,a) | \delta(s,a) \\
\delta(r \wedge s, a) & = & \delta(r,a) \wedge \delta(s,a) \\
\delta(\neg r, a) & = & \neg \delta(r,a) \\
\delta(r, \epsilon) & = & r \\
\delta(r, a \cdot u) & = & \delta(\delta(r,a),u)\ \textrm{ where $u$ is a string} \\
\delta((r_1, r_2, \ldots, r_n), a) & = & (\delta(r_1,a), \delta(r_2,a), \ldots, \delta(r_n,a))
\end{array}
$$
(While concatenation is usually represented by juxtaposition, i.e. ab, for clarity in this table I have represented it as an explicit ⋅ (no, that’s a dot, not a speck on your monitor) between two other expressions. Alternation and conjunction are represented by “|” and “∧”, respectively.)
The last three equations may require some special explanation. The first two, for δ(r, ϵ) and δ(r, au) extend the definition of a regular expression derivative, with respect to a character, into the definition of a regular expression with respect to a string. This is done straightforwardly, by defining the derivative of r with respect to ϵ to be r itself, and by defining the derivative of r with respect to a non-empty string to be the first-order derivative of r with respect to the first character, computing a second-order derivative with respect to the next character, and so on. (Taking the derivative with respect to a string is nice to be able to do, for completeness anyway, but won’t further be used in this post. See, stuff’s getting simpler already!)
The final equation describes another extension to the regular expression, the idea of a regular vector; the derivative is just the derivative of the individual components. There will be much more about this extension later, though; it is primarily important as a tool to build a scanner, where you have a number of regular expressions and are interested in the one that matches at the beginning of a longer string.
If you look closely, you will see something odd in the line defining δ(r ⋅ s, a): a function ν(r). The function ν is a nullability test, a test if the expression r describes a language that contains the empty string, ϵ. If r includes ϵ, then ν(r) ultimately evaluates to ϵ; if r doesn’t include ϵ, then ν(r) evaluates to ∅. Mathematically, ν is:
$$
\begin{array}{rcl}
\nu(\epsilon) & = & \epsilon \\
\nu(a) & = & \emptyset \\
\nu(\emptyset) & = & \emptyset \\
\nu(r \cdot s) & = & \nu(r) \wedge \nu(s) \\
\nu(r|s) & = & \nu(r) | \nu(s) \\
\nu(r*) & = & \epsilon \\
\nu(r \wedge s) & = & \nu(r) \wedge \nu(s) \\
\nu(\neg r) & = & \left\{ \begin{array}{rl}
\epsilon & \textrm{if $nu(r) = \emptyset$} \\
\emptyset & \textrm{if $nu(r) = \epsilon$}
\end{array} \right.
\end{array}
$$
The point of ν in the derivative of concatenation is, if the left component, r, is nullable, then we need to push the derivative operation onto the right component, s. Consider what happens when you take the derivative of the regular expression ab with respect to a: a is not nullable, so that equation evaluates to (ϵ ⋅ b)|(∅ ⋅ ∅), which can be simplified to ϵ ⋅ b. The derivative of that with respect to b (note that ϵ is nullable) is (∅⋅b)|(ϵ ⋅ ϵ), which simplifies to ϵ. Which is exactly what we need: the derivative of the regular expression ab with respect to the string ab should be exactly ϵ.
A brief aside about Greek letters I have an embarrassing admission to make: I never memorized the Greek alphabet. I recognize the common ones, sure, such as α, π, and λ. I even know some of the upper case: Σ and Ω. But generally, when I run across a letter in some math in some paper, well… I could look it up, but really, who does that? I generally just refer to it as “smegma”. Multiple letters? “Big smegma”, “the other smegma” and so on. It’s probably a good thing I don’t have to do this in public very often. In any case, I did look them up this time: δ is delta and ν is nu.
Now that we have a good, clean definition of the derivative of a regular expression, what can you do with it?
Regular expression matching
How about writing a proggy?
In this section, I’m going to start by presenting a basic internal representation of regular expressions, as a combination of simple expressions (ϵ, symbols, etc.) and higher-level operations on one or more lower-level expressions (concatenation, alternation, Kleene-star, etc.), plus some operations on the internal representation of expressions. Then, I’ll present a simple parser for expressions, to build the internal representation. Finally, I’ll show a regular expression matching engine using the derivative operation.
I have not written about Scheme before; in fact, this is the first serious work I’ve done in Scheme. But it seems like a nice enough language and I thought that, since I was doing programming language work, I would use one of the favorite tools for that task. Hence, Scheme, specifically Guile 2.0.11.
I may not have used Scheme before, but I do have a lot of experience with Common Lisp, although I haven’t used it seriously in quite a number of years. But one thing I have written about before is the weird love-affair that Lisp programmers have with representations over abstractions for data structures. Matt Might, in his own Scheme code for regular expression derivatives, provides some dandy examples:
;; Special regular expressions.
(define regex-NULL #f) ; -- the empty set
(define regex-BLANK #t) ; -- the empty stringYes, using Booleans for ∅ and ϵ. He even goes so far as to write, for his version of ν,
; regex-empty : regex -> boolean
(define (regex-empty re)
(cond
((regex-empty? re) #t)
((regex-null? re) #f)
((regex-atom? re) #f)
((match-seq re (lambda (pat1 pat2)
(seq (regex-empty pat1) (regex-empty pat2)))))
((match-alt re (lambda (pat1 pat2)
(alt (regex-empty pat1) (regex-empty pat2)))))
((regex-rep? re) #t)
(else #f)))Not only is that not using standard Scheme (Might is using Racket), but the only reason that function results in a Boolean is a carefully arranged accident of representation along with careful construction of the alternation and concatenation operators.
The empty set and the empty string
As a result, I’m going to follow my own advice and create a nice pile of structures. (Who’s scared of a little verbosity, anyway?) To start with, here are representations of ∅ and ϵ expressions:
(define-record-type dre-null-t ; The empty language; the empty set
(dre-null-raw) dre-null?)
(define dre-null (dre-null-raw)) ; Uninteresting value; use a constant
(define-record-type dre-empty-t ; The empty string
(dre-empty-raw) dre-empty?)
(define dre-empty (dre-empty-raw))The records use SRFI-9 record types, as recommended in the Guile documentation. Since ∅ and ϵ do not have any interesting structure, I am defining constants for them, dre-null, and dre-empty.
Character sets
I am presenting the completed proof-of-concept work here, and there are some differences between it and the simple presentation in the previous section. One of those differences is the regular vectors mentioned above (and again, later). Another is this: Rather than using single, constant characters as the base regular expressions, this code uses character sets.
The fundamental idea is that, rather than using raw symbols such as a, I use symbol sets, S, such as the set {a}. Nothing changes from the presentation above, except that the definitions
$$
\begin{array}{rcl}
\delta(a, a) & = & \epsilon\ \textrm{ when $a$ = $a$} \\
\delta(b, a) & = & \emptyset\ \textrm{ when $a$ $\neq$ $b$}
\end{array}
$$
become
$$
\begin{array}{rcl}
\delta(S, a) & = & \left\{ \begin{array}{rl}
\epsilon\ & \textrm{ when $a$ $\in$ $S$} \\
\emptyset\ & \textrm{ when $a$ $\not\in$ $S$}
\end{array} \right.
\end{array}
$$
Using character sets has a number of advantages. For one thing, trying to enumerate a large number of characters, like Unicode, would be silly. Instead, large character sets can be defined positively and negatively: a finite set of given characters, or the negation of a finite set of characters.
(define-record-type dre-chars-t ; Set of characters
(dre-chars-raw positive chars) dre-chars?
(positive dre-chars-pos?)
(chars dre-chars-set))
(define (dre-chars chars)
(dre-chars-raw #t (list->set chars)))
(define (dre-chars-neg chars)
(dre-chars-raw #f (list->set chars)))
(define dre-chars-sigma (dre-chars-neg '()))Σ is defined here as the negation of the empty set.
The basic set operations are complicated by the positive/negative distinction, but not overwhelmingly so.
(define (dre-chars-member? re ch)
(let ([is-member (set-member? (dre-chars-set re) ch)])
(if (dre-chars-pos? re) is-member (not is-member)) ))
(define (dre-chars-empty? chars)
(cond
[(not (dre-chars? chars)) (error "not a character set:" chars)]
[(dre-chars-pos? chars) (set-empty? (dre-chars-set chars))]
[else #f] ))
(define (dre-chars-intersection l r)
(cond
[(and (dre-chars-pos? l) (dre-chars-pos? r))
;; both positive: simple intersection
(dre-chars-raw #t (set-intersection (dre-chars-set l) (dre-chars-set r)))]
[(dre-chars-pos? l)
;; l positive, r negative: elts in l also in r by dre-chars-member?
(dre-chars (filter (lambda (elt) (dre-chars-member? r elt))
(set-elts (dre-chars-set l))))]
[(dre-chars-pos? r)
;; l negative, r positive: the mathematician's answer
(dre-chars-intersection r l)]
[else
;; both negative: slightly less simple union
(dre-chars-raw #f (set-union (dre-chars-set l) (dre-chars-set r)))] ))If you take a close look at dre-chars-empty?, you’ll see that a negated character set cannot be empty; it always returns false. Interesting, eh? (It means Σ is infinite.)
The implications of that appear in the one further special operation: the choice of a character from a set. It is easy if the set is positive, but if the set is negative I am using Scheme’s typelessness and taking the cheap, quick way out: returning something that cannot possibly be a member of a character set.
(define (dre-chars-choice chars)
(cond
[(not (dre-chars? chars))
(error "not a character set:" chars)]
[(and (dre-chars-pos? chars) (not (dre-chars-empty? chars)))
(car (set-elts (dre-chars-set chars)))]
[else (gensym)] ; Not a character
))dre-chars-choice is not immediately needed, but becomes important when converting a regular expression directly into a deterministic automaton, which will appear further down.
Concatenation
The concatenation of two regular expressions is represented by dre-concat-t, a record with left and right fields.
Constructing a concatenation is another moderately complicated operation.
(define-record-type dre-concat-t ; Concatenation; sequence
(dre-concat-raw left right) dre-concat?
(left dre-concat-left)
(right dre-concat-right))
(define (dre-concat left right)
(cond
[(not (dre? left))
(error "not a regular expression: " left)]
[(not (dre? right))
(error "not a regular expression: " right)]
;; ∅ ∙ r => ∅
[(dre-null? left)
dre-null]
;; r ∙ ∅ => ∅
[(dre-null? right)
dre-null]
;; ϵ ∙ r => r
[(dre-empty? left)
right]
;; r ∙ ϵ => r
[(dre-empty? right)
left]
;; (r ∙ s) ∙ t => r ∙ (s ∙ t)
[(dre-concat? left)
(dre-concat (dre-concat-left left)
(dre-concat (dre-concat-right left)
right))]
[else
(dre-concat-raw left right)]
))The idea here is to keep the structure in a “canonical” state. If either the left or right expressions is ∅, the concatenation is ∅. If the left expression is ϵ, the concatenation is simply the right expression; likewise for the right expression. Finally, a tree structure built of concatenations should be “right-heavy”: the leftmost expression should always be a non-concatenation, recursively.
This canonical structure, which will be repeated for alternation, Kleene-closure, conjunction, and negation, is used when comparing two regular expression structures for equality (or at least semi-equality; it’s still possible for two differing expressions to describe the same language). Once again, a topic that will become important when converting the expression to a DFA.
Alternation
Given that alternation in a regular expression is the same as union of the two languages described by the two expressions, the simplifications for the canonical form should be easy to see.
(define-record-type dre-or-t ; Logical or; alternation; union
(dre-or-raw left right) dre-or?
(left dre-or-left)
(right dre-or-right))
(define (dre-or left right)
(cond
[(not (dre? left))
(error "not a regular expression: " left)]
[(not (dre? right))
(error "not a regular expression: " right)]
;; ∅ + r => r
[(dre-null? left)
right]
[(dre-null? right)
left]
;; r + r => r
[(dre-equal? left right)
left]
;; ¬∅ + r => ¬∅
[(and (dre-negation? left)
(dre-null? (dre-negation-regex left)))
left]
;; (r + s) + t => r + (s + t)
[(dre-or? left)
(dre-or (dre-or-left left)
(dre-or (dre-or-right left)
right))]
[else
(dre-or-raw left right)]
))Just to keep everything notationally interesting, I have used “|” for alternation, but the “practical” paper uses “+”, and I copied the comments in the code from the paper.
Kleene closure
There are a couple of slightly odd facts about the Kleene closure.
The closure of the empty language is the language containing nothing but the empty string.
The closure of the closure of an expression, (r * )*, is the same as the unnested closure of the expression, r*.
Weird, eh?
(define-record-type dre-closure-t ; Kleene closure; repetition
(dre-closure-raw regex) dre-closure?
(regex dre-closure-regex))
(define (dre-closure regex)
(cond
[(not (dre? regex)) (error "not a regular expression: " regex)]
;; ∅* => ϵ
[(dre-null? regex) dre-empty]
;; ϵ* => ϵ
[(dre-empty? regex) dre-empty]
;; (r*)* => r*
[(dre-closure? regex) regex]
[else (dre-closure-raw regex)]
))Conjunction
Conjunction represents the intersection of the two languages, so the canonical simplifications, similar to alternation, should be self-explanatory.
Don’t you hate it when an author says, “This should be immediately clear.”
(define-record-type dre-and-t ; Logical and; intersection
(dre-and-raw left right) dre-and?
(left dre-and-left)
(right dre-and-right))
(define (dre-and left right)
(cond
[(not (dre? left))
(error "not a regular expression: " left)]
[(not (dre? right))
(error "not a regular expression: " right)]
;; ∅ & r => ∅
[(dre-null? left)
dre-null]
[(dre-null? right)
dre-null]
;; r & r => r
[(dre-equal? left right)
left]
;; (r & s) & t => r & (s & t)
[(dre-and? left)
(dre-and (dre-and-left left)
(dre-and (dre-and-right left)
right))]
;; ¬∅ & r => r
[(and (dre-negation? left)
(dre-null? (dre-negation-regex left)))
right]
[else
(dre-and-raw left right)]
))Negation
And once again, the negation of a regular expression is the complement of the language set. And the negation of a negation is the original expression and set.
(define-record-type dre-negation-t ; Complement
(dre-negation-raw regex) dre-negation?
(regex dre-negation-regex))
(define (dre-negation regex)
;; ¬(¬r) => r
(if (dre-negation? regex)
(dre-negation-regex regex)
(dre-negation-raw regex))
)Regular expression vectors
Regular expression vectors are remarkably simple, all the way through this. That is fortunate, because they become very, very important much later on.
(define-record-type dre-vector-t ; A vector of regexs
(dre-vector v) dre-vector?
(v dre-vector-list))Predicates
I am almost done with the preliminaries, I promise. Now, we have a couple of predicates that are both used in the constructors above (as well as the code below).
(define (dre? re)
(or (dre-null? re)
(dre-empty? re)
(dre-chars? re)
(dre-concat? re)
(dre-or? re)
(dre-closure? re)
(dre-and? re)
(dre-negation? re)
(dre-vector? re) ))The function dre? returns true if the argument is a regular expression and false otherwise. It’s built from the predicates for the constituent structures.
A brief aside about names I have used dre as the prefix for the structures and functions I am writing here. This stands for “Derivatives of Regular Expressions”. Possibly. Maybe. Or something. This is why I don’t get to name things.
At this point, I feel my choice of Guile Scheme is unfortunate. If I had chosen Racket, I could have called the package “Dr. Dre.” Not that I would ever actually do that. I really shouldn’t name things.
In any case, the next predicate is dre-equal?, a function to compare two regular expressions for equality.
(define (dre-equal? left right)
(cond
[(not (dre? left))
#f]
[(not (dre? right))
#f]
[(and (dre-and? left) (dre-and? right))
(let ([l1 (dre-and-left left)]
[l2 (dre-and-right left)]
[r1 (dre-and-left right)]
[r2 (dre-and-right right)])
(or (and (dre-equal? l1 r1)
(dre-equal? l2 r2))
(and (dre-equal? l1 r2)
(dre-equal? l2 r1))))]
[(and (dre-or? left) (dre-or? right))
(let ([l1 (dre-or-left left)]
[l2 (dre-or-right left)]
[r1 (dre-or-left right)]
[r2 (dre-or-right right)])
(or (and (dre-equal? l1 r1)
(dre-equal? l2 r2))
(and (dre-equal? l1 r2)
(dre-equal? l2 r1))))]
[(and (dre-vector? left) (dre-vector? right))
(every dre-equal?
(dre-vector-list left)
(dre-vector-list right))]
[else
(equal? left right)]
))Truly comparing expressions for equality is probably undecidable; it would involve deciding whether they represented the same languages, which is the same kind of problem as deciding whether two functions produce the same output given the same inputs.
What this predicate is doing is comparing the two expressions for limited, structural, equality, with the additional proviso that dre-and and dre-or are symmetric—the order of the arguments doesn’t matter. This, combined with the (minimal) work I put into making the structural representations canonical ought to be good enough, especially since any two expressions being compared were probably derived from some single previous expression.
“Good enough”, in this case, means optimizing the structures above (where minor problems will not affect their semantics) and minimizing the number of states below (much further below, where the argument that the expressions are derived from a single parent is probably more important for correctness).
Parsing regular expressions
At this point, I have the structural tools to create representations of regular expressions by gluing things together by hand. But I would very much like not to do that. So, I have (ahem) borrowed a recursive-descent regex parser from Matt Might.
The original grammar (I’ve modified it a bit, specifically to extend to more regular expressions) was:
$$
\begin{array}{rcl}
\textit{regex} & := & \textit{term}\ \textbf{|}\ \textit{regex} \\
& | & \textit{term} \\
\textit{term} & := & \{ \textit{factor} \} \\
\textit{factor} & := & \textit{base} \{ \textbf{*} \} \\
\textit{base} & := & \textit{char} \\
& | & \textbf{(}\ \textit{regex}\ \textbf{)} \\
& | & \textbf{[}\ \textit{set}\ \textbf{]} \\
\textit{set} & := & \{ \textit{char} \} \\
& | & \textbf{^}\ \{ \textit{char} \} \\
\textit{char} & := & \textrm{character} \\
& | & \textbf{\\}\ \textrm{character}
\end{array}
$$
The parser is string->dre; given a string, it produces a regular expression built from the structures above. It reads from a string argument and uses the value cur to record its current location in the string.
(define (string->dre str)
(let ([cur 0])
;; Peek at the next character
(define (peek)
(if (more) (string-ref str cur) (error "unexpected end of string")))
;; Advance past the next character
(define (eat ch)
(if (char=? ch (peek)) (set! cur (+ cur 1))
(error "unexpected character:" ch (peek))))
;; Eat and return the next character
(define (next)
(let ([ch (peek)]) (eat ch) ch))
;; Is more input available?
(define (more)
(< cur (string-length str)))
;; The regex rule
(define (regex)
(let ([trm (term)])
(cond
[(and (more) (char=? (peek) #\|))
(eat #\|)
(dre-or trm (regex))]
[else
trm]
)))
;; The term rule
(define (term)
(let loop ([fact dre-empty])
(cond
[(and (more) (and (not (char=? (peek) #\)))
(not (char=? (peek) #\|))))
(loop (dre-concat fact (factor)))]
[else
fact]
)))
;; The factor rule
(define (factor)
(let loop ([b (base)])
(cond
[(and (more) (char=? (peek) #\*))
(eat #\*)
(loop (dre-closure b))]
[else
b]
)))
;; The base rule
(define (base)
(cond
[(char=? (peek) #\()
;; parenthesized sub-pattern
(eat #\()
(let ([r (regex)])
(eat #\))
r)]
[(char=? (peek) #\[)
;; character set
(eat #\[)
(let ([s (set)])
(eat #\])
s)]
[(char=? (peek) #\.)
;; any character except newline
(eat #\.)
(dre-chars-neg '(#\newline))]
[else
;; single character
(dre-chars (list (char)))]
))
;; The set rule
(define (set)
(cond
[(char=? (peek) #\^)
;; negated set
(eat #\^)
(dre-chars-neg (chars))]
[else
;; positive set
(dre-chars (chars))]
))
;; The chars rule
(define (chars)
(let loop ([ch '()])
(if (char=? (peek) #\])
ch
(loop (cons (char) ch)))))
;; The char rule
(define (char)
(cond
[(char=? (peek) #\\)
;; quoted character
(eat #\\)
(next)]
[else
;; unquoted character
(next)]
))
;; Read the regex from the string
(let ([r (regex)])
(if (more)
(error "incomplete regular expression:" (substring str cur))
r))
))Note the brilliant use of lexical scoping, to enclose the functions implementing the grammar rules, which simplifies their interfaces and hides them from the outside. Lexical scoping is damn nice.
Delta and nu
And finally, I reach the heart of regular expression derivatives: implementing the functions δ and ν. They are actually pretty trivial, simply translating the definitions above to use the structures and functions that I’ve defined.
The function ν is first, implemented as nu.
(define (nu re)
(cond
[(not (dre? re))
(error "not a regular expression: " re)]
[(dre-empty? re)
dre-empty]
[(dre-chars? re)
dre-null]
[(dre-null? re)
dre-null]
[(dre-concat? re)
(dre-and (nu (dre-concat-left re))
(nu (dre-concat-right re)))]
[(dre-or? re)
(dre-or (nu (dre-or-left re))
(nu (dre-or-right re)))]
[(dre-closure? re)
dre-empty]
[(dre-and? re)
(dre-and (nu (dre-and-left re))
(nu (dre-and-right re)))]
[(dre-negation? re)
(if (dre-null? (nu (dre-negation-regex re)))
dre-empty
dre-null)]
))The second function is δ, implemented as delta.
(define (delta re ch)
(cond
[(not (dre? re))
(error "not a regular expression: " re)]
[(dre-empty? re)
dre-null]
[(dre-null? re)
dre-null]
[(dre-chars? re)
(if (dre-chars-member? re ch) dre-empty dre-null)]
[(dre-concat? re)
(dre-or (dre-concat (delta (dre-concat-left re) ch)
(dre-concat-right re))
(dre-concat (nu (dre-concat-left re))
(delta (dre-concat-right re) ch)))]
[(dre-closure? re)
(dre-concat (delta (dre-closure-regex re) ch) re)]
[(dre-or? re)
(dre-or (delta (dre-or-left re) ch)
(delta (dre-or-right re) ch))]
[(dre-and? re)
(dre-and (delta (dre-and-left re) ch)
(delta (dre-and-right re) ch))]
[(dre-negation? re)
(dre-negation (delta (dre-negation-regex re) ch))]
[(dre-vector? re)
(dre-vector (map (lambda (r) (delta r ch))
(dre-vector-list re)))]
))Matching
Ok, so now I have code for representing regular expressions, parsing them, and computing their derivatives with respect to a character. What can I do with it?
How about a simple, quick, and dirty regular expression matcher?
(define (dre-match-list? re list)
(cond
[(null? list) (dre-empty? (nu re))]
[else (dre-match-list? (delta re (car list)) (cdr list))]
))
(define (dre-match? re str) (dre-match-list? re (string->list str)))dre-match? returns true if the expression matches the string and false otherwise. It does this by recursively computing the derivative of the starting regular expression with respect to each character in the string, in order. When the end of the string is reached, the regular expression is declared to match if it matches the empty string, using ν (in case the current expression has some significant structure).
Things don’t really get much simpler than that.
How does it work? Pretty well:
> (dre-match? (string->dre "ab") "ab")
$2 = #t
> (dre-match? (string->dre "ab*") "abbb")
$3 = #t
> (dre-match? (string->dre "ab*") "acbb")
$4 = #f
> (dre-match? (string->dre "\"[^\"]*\"") "\"A string!\"")
$5 = #t
> (dre-match? (string->dre "\"[^\"]*\"") "\"A string!\" not really")
$6 = #f
> (dre-match? (string->dre "\"[^\"]*\"") "\"A \\\"silly\\\" string!\"")
$7 = #f
> (dre-match? (string->dre "\"(\\\"\|[^\"])*\"") "\"A \\\"silly\\\" string!\"")
$8 = #tI apologize for the extra backslashes there. The string in the fourth example is “A string!”; the regex is “[^"]*“. The final example shows regular expressions which match quoted strings with escaped quotes inside.
Converting a regular expression to a DFA
I know what you’re thinking. You’re saying to yourself, “We went through all that and now we have a moderately poor, slow, regular expression matcher. Yay.” But there are two points to consider:
By my count, including blank lines and comments, and some stuff that I haven’t shown (I had to implement my own set for characters, and I wrote pretty-printers for the structures), we are at about 600 lines. Yeah, that’s not great, but I haven’t been trying to compress things, either.
That’s not all of the fun we can have here. Using derivative techniques, I can convert a regular expression into a deterministic finite automaton. Without first creating a non-deterministic finite automaton, which is the usual process as described in the Dragon book, for example.
This section begins by describing deterministic finite automata and discusses one minor road bump in building one from a regular expression: character sets. Then I go into the Scheme code for finite automata and finally describe the direct conversion from regular expressions to DFAs. Finally, I cover how to use the resulting DFA to build a lexical scanner.
What is a deterministic finite automaton?
“What’s a deterministic finite automaton?” you’re asking. (Well, maybe not. If not, you can probably take another nap through this section.)
An automaton in this context is a machine for recognizing strings that are in a given language, as opposed to strings that are not in the language. A finite state automaton is a machine that has a finite number of states. (Ok, that was just redundant.) Unlike other automatons which have external memory, like the stacks of a stack automaton or the tape of a Turing machine, a FA only has a fixed number of states that it can be in. It reads a character, makes a transition into another state or possibly the same one, and then looks to read another character. If the machine is an accepting state when the last character has been read, the string is declared to be in the language.
The following illustration shows a DFA for ab * c.
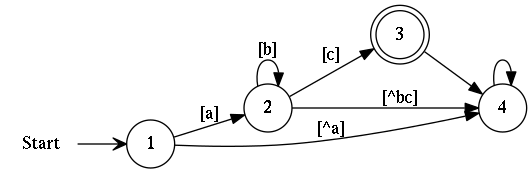
A DFA for ab*c
State 1 is the starting state, state 3 is accepting, and each edge is either labeled with a character set or not labeled, indicating any character.
More formally, a FA is a directed graph made of nodes (representing states), S, and edges (representing transitions), T. A state s ∈ S has three important properties:
An identity—each node can be distinguished from every other node.
Whether or not the node is a starting node for the machine. There is only one starting node in a given FA.5
Whether or not the node is an accepting node for the machine. There can be any number of accepting nodes (although there should be at least one, otherwise the language will be ∅).
A transition t ∈ T is a triple of three elements, (s, c, s′). The initial state for the transition is s; c is an input character (or a set of input characters), and s′ is a destination state. What the transition t means is that when the FA is in state s, if it sees a character in c, then it moves to state s′.
A deterministic finite automaton is an FA were every state has exactly one outgoing transition for every possible input character. As a result, when reading a character, the machine does not need to make any choices; it just matches the current state and the input character to determine the single possible destination state.
“Great!” you say, “Wonderful! But, so what?” A DFA is the fastest way to do regular expression matching. It won’t work for all the fancy features of other regular expression engines, and there are techniques that it cannot match, like using a fast string-search algorithm to look for fixed strings. But a DFA is an O(n) algorithm with very fast constants, if you can determine which transition matches an input character quickly—frequently this is a table look-up.
Now, about those input characters…
Character sets
When doing anything with regular expressions, there is a very basic question that I have not asked until now: What are your characters, and how are you handling them? This question suddenly becomes important right at this point.
Up to this point, the answer is pretty simple: we have positive and negative sets of finite numbers of characters and the only operations we have used has been construction and a membership test. But, I defined all those extra operations…
Here’s the deal: traditional DFA construction algorithms iterate over all characters in the alphabet, Σ, to identify the transitions leaving a state. In effect, if not in practice, they build a matrix where the rows are states and there is one column for all possible input characters; the value of each entry is the next state to enter.
That approach is feasible for small alphabets, such as 7-bit ASCII or 8-bit ISO8859-1 (or -2, or -9, and I hope you’re seeing the problem). But it will not work at all for a Unicode alphabet.
Instead, “Regular expression derivatives reexamined” provides a suggested extension to Brzozowski’s original work on DFA construction using regular expression derivatives, using character sets (which I have been following all along) and computing approximate equivalence classes of characters for each state to identify the outgoing transitions. To quote the paper,
Given an RE r over Σ, and symbols a and b ∈ Σ, we say that a ≃r b if and only if δ(r, a) ≡ δ(r, b) [notation modifed]. The derivative classes of r are the equivalence classes Σ/≃r.
In other words, the derivative classes divide up Σ in such a way that all of the symbols in a given derivative class compute the same derivative expression from a starting expression r.
Computing these derivative classes exactly would require iteration over the elements of Σ, which is exactly what we’re trying to avoid. Fortunately, the authors of the paper are able to define a function C by recursing over the structure of r that computes an approximation of the derivative classes.
In effect, given a regular expression r, C returns a partitioning of Σ into sets of characters, the derivative classes, that cause r to behave differently. This partitioning is approximate; two characters a and b that cause r to “do the same thing” may end up in different derivative classes, but the authors prove that all of the characters in the same derivative class cause r to behave the same way.
One thing that is important to note: each derivative class is a character set, the same structures that we have been using all along to handle input.
C is:
$$
\begin{array}{rcl}
C(\epsilon) & = & \{ \Sigma \} \\
C(S) & = & \{ S, \Sigma\setminus S \} \textrm{ where $\Sigma\setminus S$ is the negation of $S$} \\
C(r\ \cdot\ s) & = & \left\{ \begin{array}{l;l}
C(r) & \textrm{ when $r$ is not nullable } \\
C(r)\ \hat\cap\ C(s) & \textrm{ otherwise }
\end{array} \right. \\
C(r | s) & = & C(r)\ \hat\cap\ C(s) \\
C(r \wedge s) & = & C(r)\ \hat\cap\ C(s) \\
C(r*) & = & C(r) \\
C(\neg r) & = & C(r)
\end{array}
$$
Notational note This is one of the most notationally crazed papers I’ve read in a long time. What I have rendered as
$$c_1 \hat\cap\ c_2$$
is ∧ in the paper, and while most of the definitions are equational like C, there is still another oddity coming up.
Speaking of that function (you know, intersection wearing a hat), it is defined as:
$$
C(r)\ \hat\cap\ C(s) = \{ S_r \cap S_s | S_r \in C(r), S_s \in C(s) \}
$$
i.e. the set consisting of the pair-wise intersection of all of the members of C(r) with the members of C(s).
In Scheme, C and and its auxiliary are defined as follows:
(define (C re)
(cond
[(dre-empty? re)
(set dre-chars-sigma)]
[(dre-chars? re)
(let ([elts (set-elts (dre-chars-set re))])
(set (dre-chars elts)
(dre-chars-neg elts)))]
[(dre-concat? re)
(let ([r (dre-concat-left re)]
[s (dre-concat-right re)])
(if (dre-empty? (nu r))
(C-hat (C r) (C s))
(C r)))]
[(dre-or? re)
(C-hat (C (dre-or-left re)) (C (dre-or-right re)))]
[(dre-and? re)
(C-hat (C (dre-and-left re)) (C (dre-and-right re)))]
[(dre-closure? re)
(C (dre-closure-regex re))]
[(dre-negation? re)
(C (dre-negation-regex re))]
[(dre-null? re)
(set dre-chars-sigma)]
[(dre-vector? re)
(fold C-hat
(set dre-chars-sigma)
(map C (dre-vector-list re)))]
[else
(error "unhelpful regular expression:" re)]
))(Oh, and the auxiliary (whose name I apparently cannot use inline, thanks MathJAX) is called C-hat for simplicity and defined using a SRFI-42 list comprehension.)
(define (C-hat r s)
;; pair-wise intersection of two sets of character
(list->set (list-ec (:list elt-r (set-elts r))
(:list elt-s (set-elts s))
(dre-chars-intersection elt-r elt-s))))And C-hat uses dre-chars-intersection, another of the dre-chars operations.
Now, since we have the input character question settled, I can get on with building a deterministic finite-state automaton.
States, transitions, and machines
As I mentioned before, a state has three important properties: an identity, whether it is a starting state and whether it is an accepting state. And, as there is only one starting node, that property is pretty unimpressive. For purposes of implementing a transformation to a DFA, a state structure such as dre-state-t has some extra fields.
dre-state-number: This is the effective identify of the state.dre-state-regex: Given that the regular expression system I’m building is based on the calculation of the derivative of a regular expression with respect to an input character, which is itself a regular expression, it is possible to label each state with the regular expression that represents what the automata would accept, starting from this state.dre-state-accepting: True if the state is accepting, false otherwise. (Ignore the regular expression vector lurking behind the curtain. More on it later.)dre-state-null: True if the state is an error state: one from which there is no accepting string.
(define-record-type dre-state-t ; A state in the machine
(dre-state-raw n re accept null) dre-state?
(n dre-state-number)
(re dre-state-regex)
(accept dre-state-accepting)
(null dre-state-null))dre-state uses a lexically-scoped counter to generate the state numbers. If you haven’t seen an example of that particular linguistic feature, well, you can’t say that any more.
It also has two auxiliary functions: accepting, which sets dre-state-accepting depending on the regular expression label, and nulling, which sets dre-state-null, also depending on the regular expression.
(define dre-state
(let ([state-count 0])
(lambda (re)
(define (accepting re)
(cond
[(dre-vector? re) (map accepting (dre-vector-list re))]
[else (dre-empty? (nu re))] ))
(define (nulling re)
(cond
[(dre-vector? re)
(every (lambda (b) b) (map nulling (dre-vector-list re)))]
[else
(dre-null? re)] ))
(set! state-count (+ state-count 1))
(let* ([accept
(accepting re)]
[error-state
(nulling re)])
(dre-state-raw state-count re accept error-state)))))The machine also needs to record transitions. These contain two states, an origin and a destination, and the character set labeling the transition.
(define-record-type dre-transition-t ; <state, input, state'> transition
(dre-transition state input state') dre-transition?
(state dre-transition-origin)
(input dre-transition-input)
(state' dre-transition-destination))Finally, there is the deterministic finite state machine itself, made up of a group of states, a group of transitions, and the identified start state.
(define-record-type dre-machine-t ; Finite state machine
(dre-machine states start transitions) dre-machine?
(states dre-machine-states)
(start dre-machine-start)
(transitions dre-machine-transitions))The function dre-transitions-for implements the process of picking out the transitions whose origin is a given state.
(define (dre-transitions-for machine state)
(let ([state-num (dre-state-number state)])
(remove (lambda (trans)
(not (eq? state-num
(dre-state-number (dre-transition-origin trans)))))
(set-elts (dre-machine-transitions machine)))))Conversion
Finally, we have all of the components necessary to convert a regular expression directly into a deterministic finite automaton.
The basic idea is to create a state, si, labeled with a regular expression. Then, compute the derivative classes for the regular expression. For each class, pick out a representative member using dre-chars-choice and use it to compute the derivative of the regular expression. If this new expression is equivalent to the expression labeling an existing state (using dre-equal?), say sj, record a transition from si to sj associated with the derivative class. If the new expression is not equivalent to any existing state’s label, create a new state for it, sk, and record the transition from si to sk. Follow this process recursively until all states have had all derivative classes examined.
The result is a deterministic finite state automaton.
Another note on notation This is the final place where “Regular-expression derivatives reexamined” gets a little wacky. The algorithm for this transformation, unlike everything else in the paper, is given in mutually recursive pseudocode. Fortunately, it is very close to the Scheme code below.
(define (dre->dfa r)
(define (goto q S engine)
(let* ([Q (car engine)]
[d (cdr engine)]
[c (dre-chars-choice S)]
[qc (delta (dre-state-regex q) c)]
[q' (set-find Q (lambda (q') (dre-equal? (dre-state-regex q') qc)))])
(if q'
(cons Q (set-union d (set (dre-transition q S q'))))
(let ([q' (dre-state qc)])
(explore (set-union Q (set q'))
(set-union d (set (dre-transition q S q')))
q')) )))
(define (explore Q d q)
(fold (lambda (S engine) (goto q S engine))
(cons Q d)
(remove dre-chars-empty?
(set-elts (C (dre-state-regex q))))))
(let* ([q0 (dre-state r)]
[engine (explore (set q0) (set) q0)]
[states (car engine)]
[transitions (cdr engine)])
(dre-machine states q0 transitions)
))There are a few minor nits left to pick.
explorecomputes the derivative classes for the labels of each visited state, then callsgotowith each. It filters out empty character sets (usingdre-chars-empty?) since (a) those don’t have any members to be representative, and (b) an empty set wouldn’t be a meaningful transition anyway.gotopicks a representative element from the derivative class / character set, uses it to compute the derivative, and makes the choice on whether a new state should be added. If you recalldre-chars-choice, it returns a character from the set if the set is positive and a newly generated Scheme symbol if it isn’t. The symbol is a valid argument todre-chars-member?which is used when computing the derivative, which is good since the symbol is used to represent any character outside the (negative) set, which would otherwise be potentially painful to identify.
What do you do with a DFA?
Computing a DFA, any way you do it, is a fairly expensive operation. Further, deterministic regular expression engines are unable to use the fancy, more-powerful-than-regular-expressions features of non-deterministic engines such as PCRE. So, what can you do with one?
There is one simple answer: lexical analysis. The scanner part of a parser.
The limitations of a DFA are less cumbersome when you are picking the next token from an input stream. The DFA can be precomputed, meaning that the expense of creating the DFA does not hurt the parser execution. Further, according to the authors of “Regular-expression derivatives reexamined”, the DFA created using this method, while it may have more than the optimal number of states, has fewer states than those created from the traditional method. And finally, running a DFA across an input string is an O(n) operation, where n is the length of the input.
Here’s how it works: a lexical analyzer is specified as a list of regular expressions; one for identifiers, one for numbers, one for each keyword, etc. This is where the regular vectors enter the picture. Each of the individual expressions is an element of the vector, which is treated as a single, extended regular expression while creating the DFA. At the end of the process, you have a single finite automaton whose states are the combination of the individual regular expressions.
And this is where we wrap up dre-state-accepting and dre-state-null. A null state, s∅, is one in which all of the elements of the vector are dre-null, ∅. In this state, it is impossible for the machine to match any input, no matter what follows. As a result, the state si, with a transition into a null state marks the end of a token.
Which token? dre-state-accepting, called on si, returns a vector of booleans, one for each element of the regular vector. If, in state si, there is only one accepting element, then that element identifies the regular expression for a token t—t is the token that should be passed on.
If there are more than one accepting elements in state si, then theoretically you might have an error in your scanner specification. However, treating that as an error places very harsh requirements on the token regular expressions; the expressions for keywords, such as “if” and “then” frequently overlap with the expressions for identifiers, say. It would be better to use some ordering, such as the order of token specifications, to resolve this ambiguity.
On the other hand, if there are no accepting elements in si, then you do have a problem. This would be a lexical error. Fortunately, I note that it would be trivial to identify states creating this error at the time the DFA is generated, by scanning the incoming transitions to s∅.
Derivative parsing
So, in one paper and in a fairly small amount of code (about 770 lines of my very verbose Scheme), I have demonstrated a regular expression parser, matcher, and the conversion to a deterministic finite automaton, with extensions to allow the straightforward construction of a lexical analyzer.
And some people think regular expression derivatives aren’t cool.
Back up at the top, I mentioned that I was interested in parser derivatives because regular expression derivatives were so nice. Unfortunately, things like On the Complexity and Performance of Parsing with Derivatives have brought me to believe that parser derivatives are less cool. Sure, the specification is even simpler than that of regular expressions here. On the other hand, though, there are a number of complications that require memoization, laziness, and computing fixed points.
None of those is particularly difficult, but the combination will be pretty hairy in a more complicated language than Scheme. Further, getting acceptable performance seems to require very tight coding to avoid very slow parsing.
As a result, although I have here the beginning of a very nice scanner using regular expression derivatives, I am currently exploring other context-free grammar parsing algorithms; specifically I am focusing on the Earley algorithm. Let’s see how that goes.
Feety Notes6
Ahem. Let’s see: Link o’ the day: Matt Might on parsing with derivatives, Parsing with derivatives: introduction, Parsing with derivatives: recursion, and Parsing with derivatives: compaction.↩
Software Tools in Haskell, Chapter 5: Text patterns; Monads and regular expressions; Variations on the theme of monadic regular expressions: Abstraction; Variations on the theme of monadic regular expressions: Records; Variations on the theme of monadic regular expressions: Back references; as well as a post on the specific paper that I am going to be looking at here: Practical regular expression derivatives.↩
Many regular expression engines in use have expressions that are extended with more powerful features, like back-references and the giant bag of things in Perl compatible regular expressions. Strictly speaking, the result is not a regular expression. Mathematically, they are much more powerful than the basic expressions that I have described here, and further (jumping ahead), they cannot be converted to deterministic finite state machines (to my knowledge). So I’m ignoring them.↩
The mathematical theory is fine with multiple starting nodes, but handling them simply uses nondeterminism, which I’m avoiding like the plague. Further, automaton constructed using this method only have one start state anyway.↩
These are like footnotes, but more warm and comforting. Like feety pajamas.↩